 |
| Expected and actual results for an example sentence from TMSB: Inside the Earth. |
The Parser tags each word with its part of speech and role in the sentence (subject, direct object, etc.). It provides a summary of the sentence structure. The Interpreter uses this information to detect the next layer of meaning: what is this sentence trying to say? E.g. is it a statement, question, or command? Does it describe a category membership, a state of being, an event, a desire? The Interpreter consumes a sentence structure and emits a more abstract knowledge representation, the "gist" of the sentence, if you will.
I redesigned the Interpreter to expand all compound sentence parts into full representations. For example, given "Jack and Jill eat beans," the Interpreter will output something akin to {AND, ["Jack->eat->beans", "Jill->eat->beans"]} ... as opposed to "{AND, [Jack,Jill]}->eat->beans". This simplifies downstream processing, since I can just loop over the list of complete atomic facts, instead of modifying all the inference tools and other machinery to handle the bewildering variety of possible sentence branches.
That upgraded the formatting at the Interpreter output as well, so the CE and NE had to be adapted as well. I did a quick-and-dirty job on the CE; it will accept the new format so as to maintain previous functionality, but it ignores anything beyond the first entry in a compound output. I put my efforts into the NE. It will process all facts from a compound, though it is not yet capable of handling multiple/nested compounds in a sentence, and it doesn't grasp the meaning of OR. Despite all those caveats, I was able to revise the "Horatio and Crispin" story.
Original Version:
0:"Horatio Nullbuilt was a robot."
1:"Crispin Horatiobuilt was a robot."
2:"Crispin could fly."
3:"A lamp was on a shelf."
4:"Horatio wanted the lamp."
5:"Horatio could not reach the lamp."
6:"Crispin hovered beside the shelf."
7:"Horatio told Crispin to move the lamp."
8:"Crispin pushed the lamp off the shelf."
9:"Horatio could reach the lamp."
10:"Horatio got the lamp."
11:"The end."
New Version:
0:"Horatio Nullbuilt and Crispin Horatiobuilt were robots."
1:"Crispin could fly."
2:"A lamp was on a shelf."
3:"Horatio wanted the lamp, but Horatio could not reach the lamp."
4:"Crispin hovered beside the shelf."
5:"Horatio told Crispin to move the lamp."
6:"Crispin pushed the lamp off the shelf."
7:"Horatio could reach the lamp."
8:"Horatio got the lamp."
9:"The end."
The New Version sounds a lot more natural, and Acuitas can process it just as well as the original.
Now for some performance assessment! I reformatted my benchmark test sets and ran them through the new Parser. You can read more about the test sets in a previous post, but here's a quick review: the text is drawn from two real children's books: The Magic School Bus: Inside the Earth, and Out of the Dark. Sentences that contain quotations have been broken in two, and abbreviations have been expanded. When a test is run, each sentence from the test set is parsed, and the output data structure is compared to a "golden" example (supplied by me) that expresses a correct way of interpreting the sentence structure. There are four categories in the results:
CORRECT: The Parser's output matched the golden example.
INCORRECT: The Parser's output did not match the golden example.
UNPARSED: No golden example was supplied for this sentence, because it contains grammar features the Parser simply does not support yet. However, the Parser did process it and generate an (incorrect) output without crashing.
CRASHED: Oh dear, the Parser threw an exception and never generated an output. Happily, membership in this category is zero at the moment.
For all sentences in the CORRECT and INCORRECT categories, the test uses Graphviz to generate diagrams of both the Parser's output and the golden example. This enables quick visual comparisons of the expected and actual results. Results from the July 2021 tests are available here. The most recent benchmark results can be downloaded from the links below. Each ZIP contains a text file with parser output and unparsed/incorrect/correct breakdowns, and a PDF of golden/actual sentence diagrams for all sentences on which parsing was attempted.
Out of the Dark - Acuitas Parser Results 02-09-2022
The Magic School Bus: Inside the Earth - Acuitas Parser Results 02-19-2022
The text of The Magic School Bus: Inside the Earth is copyright 1987 to Joanna Cole, publisher Scholastic Inc. Out of the Dark, by Tennant Redbank, is copyright 2010 to Disney Enterprises Inc. Text from these works is reproduced as part of the test results under Fair Use for research purposes. I.e. it's only here so you can see how good my AI is at reading real human books. If you want to read the books yourself, please go buy them. (Disney, don't sue me.)
Adding coordinating conjunction support to the Parser moved 10 sentences in the Out of the Dark test set out of the UNPARSED category, and moved 7 sentences in the Inside the Earth set out of UNPARSED. In both cases the majority of the newly parsed sentences went into CORRECT, although some had ambiguities or other quirks which the Parser cannot yet resolve.
Here are the summary results showing improvement since I started benchmarking the Parser last year.

Tabular Parser results showing number of sentences per category (top) and percentage per category (bottom)


And now, for some more highlight examples of the newly parsable sentences. Here's a good one:

A failure! "Flash" gets interpreted as a verb (we haven't got proper sense disambiguation yet) and things go downhill from there.

Some more good ones:


Oops! Here we have an attachment ambiguity for the phrase "in the class" (which word does it modify?), and "every" is getting treated as an adjective direct object for some wacky reason.
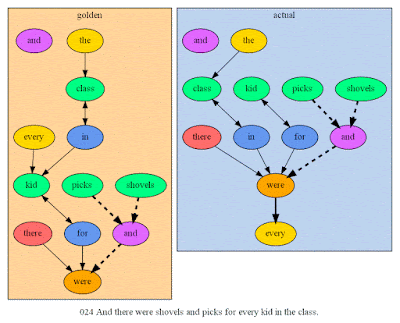 |
And another nice example:
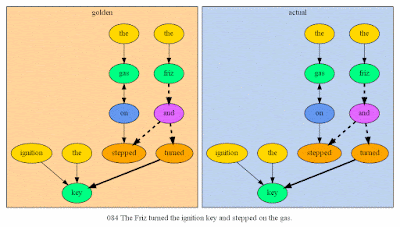 |
Until the next cycle,
Jenny
Congratulations on a noble effort.
ReplyDeleteVery interesting, thank you. I'm working on NLU also.
ReplyDelete